
常遇到一般性的非线性规划问题:
s.t.
具体工作(逗比小电工)中,一般有
而约束条件经常只是
但是目标函数较为复杂,
类似这样的问题,有什么比(yue)较(ding)好(su)的(cheng)算法吗?考虑因素有
1. 希望在各种随(bu)机(fu)选(ze)取(ren)的初值下都能找到优化点,
2. 开发的速度,中间可能会调用多个商业软件,所以越简单越好,
3. 算法的速度,越快越好,但这不是决定性的。
看到有人推荐用Differential Evolution,但这货不保证能得到全局优化解。Excel带了个solver包,用了简单粗暴的Generalized Reduced Gradient和另一个类似GA(?)的算法,试过效果很一般,似乎LS问题都处理不好。还有Down Hill Simplex似乎能保证找得到全局最优,但为什么有这样的算法存在,人们还不断另辟蹊径呢?
其他高大上的就没见过了。豹纸喵也是这个领域的新人,只从书上看到过Simulated Anealing,Genetic Algorithm和Artificial Neural Network,却从来没见过什么地方实用过的。曾被高人提示过把SA加到Down Hill Simplex里面,写出来的程序运行起来一塌糊涂……
算法是创造智能应用/智能产品的基石
基于仿生/模拟算法:
人工神经网络
深度学习
遗传算法
人工免疫算法
蚁群算法
粒子群算法
人工鱼群算法
文化算法
禁忌搜索算法
模拟退火算法
基于数学理论算法:
线性规划
回归分析
梯度下降
K近邻算法
SVM支持向量机
朴素贝叶斯
决策树
图论算法
并行算法
模糊数学
混沌算法
马尔可夫链
如果你问工程上实用价值最高,那就必须考虑算法计算量和复杂度。 粒子群这种意味着有很多例子很多采样,而实际系统这样可以实现吗?毕竟是现有系统硬件再有算法应用。 总不能为了算法去大改硬件。 如果这样考虑,建议试试天牛须搜索算法,也是类似粒子群优化,但是本质区别是1.只需要一只天牛,而非一群。2. 收敛很快,精度很高。3最关键的是核心代码只有4行,其他算法可能只能电脑上跑,别想去单篇机实现,而天牛须只有4行核心代码,不需要调用任何库函数,所以,你可以轻松的在单片机实现。作为工程应用,或许这很重要。 天牛须搜索算法(BAS) 核心代码只有4行
霸王龙优化算法(Tyrannosaurus optimization,TROA)由Venkata Satya Durga Manohar Sahu等人于2023年提出,该算法模拟霸王龙的狩猎行为,具有搜索速度快等优势。

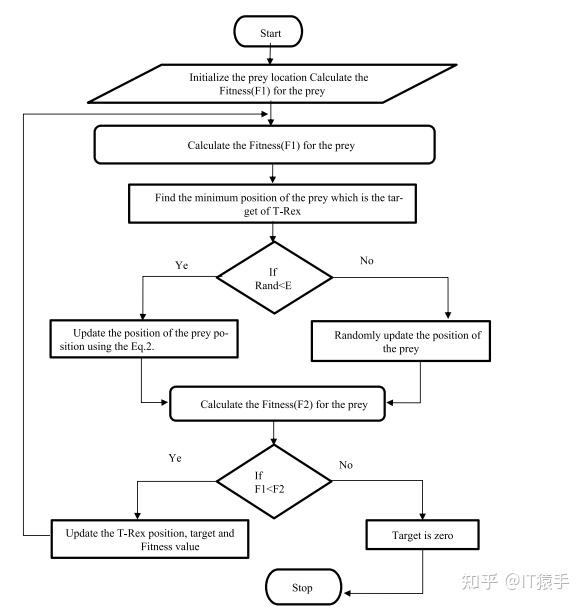
参考文献:Venkata Satya Durga Manohar Sahu, Padarbinda Samal, Chinmoy Kumar Panigrahi,”Tyrannosaurus optimization algorithm: A new nature-inspired meta-heuristic algorithm for solving optimal control problems”,e-Prime - Advances in Electrical Engineering, Electronics and Energy,Volume 5,2023,100243,ISSN 2772-6711,https://doi.org/10.1016/j.prime.2023.100243.
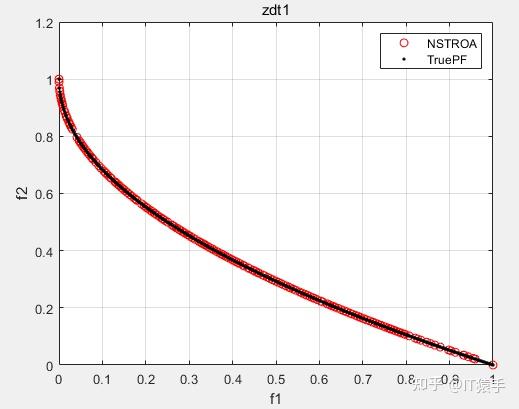
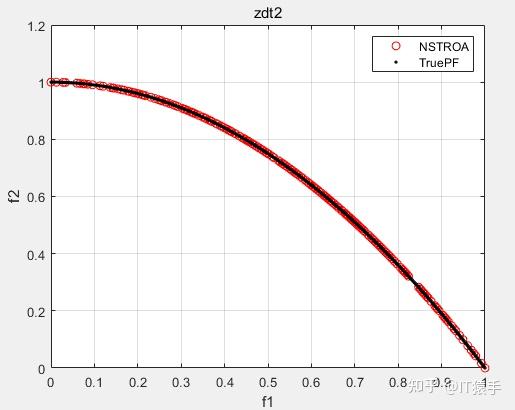
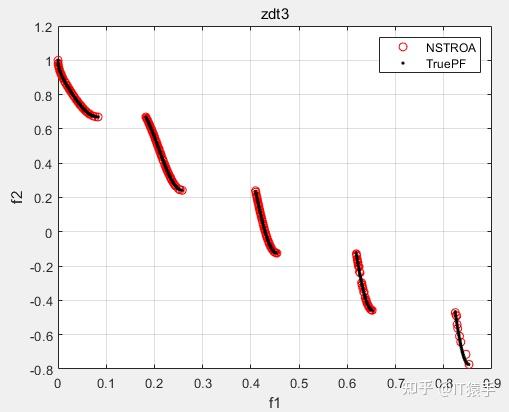
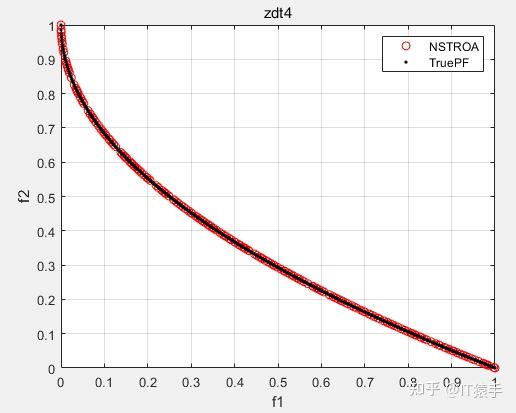
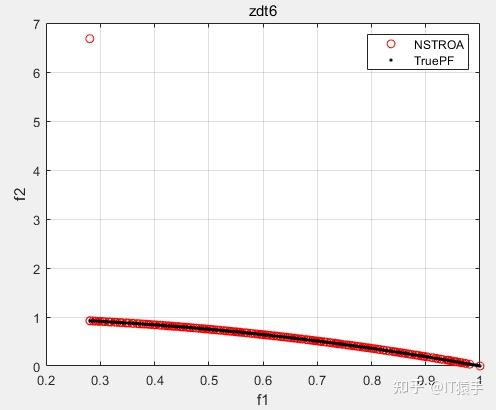
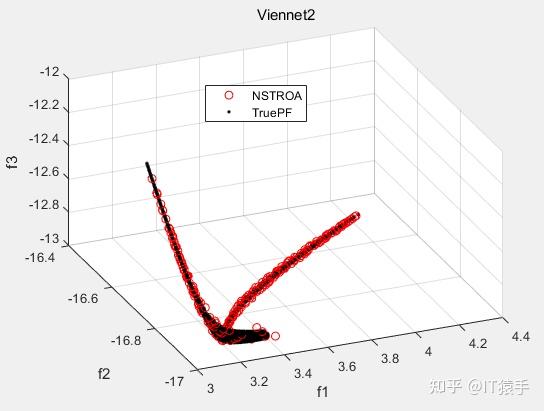
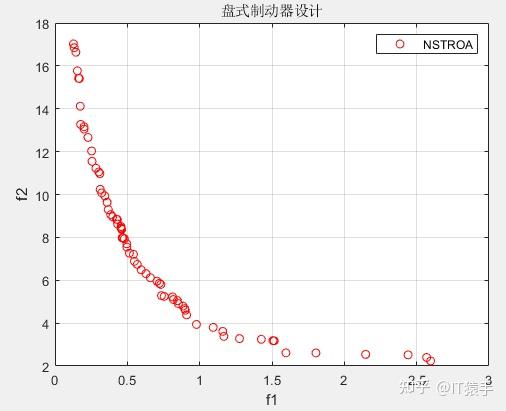
基于非支配排序的霸王龙优化算法(Non-Dominated Tyrannosaurus optimization,NSTROA)由霸王龙优化算法与非支配排序策略结合而成。将NSTROA用于求解46个多目标测试函数(ZDT1、ZDT2、ZDT3、ZDT4、ZDT6、DTLZ1-DTLZ7、WFG1-WFG10、UF1-UF10、CF1-CF10、Kursawe、Poloni、Viennet2、Viennet3)以及1个工程应用(盘式制动器设计),并采用IGD、GD、HV、SP进行评价。
(1)部分代码
close all;
clear ;
clc;
%%
% TestProblem测试问题说明:
%一共46个多目标测试函数,详情如下:
%1-5:ZDT1、ZDT2、ZDT3、ZDT4、ZDT6
%6-12:DZDT1-DZDT7
%13-22:wfg1-wfg10
%23-32:uf1-uf10
%33-42:cf1-cf10
%43-46:Kursawe、Poloni、Viennet2、Viennet3
%47 盘式制动器设计 温泽宇,谢珺,谢刚,续欣莹.基于新型拥挤度距离的多目标麻雀搜索算法[J].计算机工程与应用,2021,57(22):102-109.
%%
TestProblem=1;%1-47
MultiObj=GetFunInfo(TestProblem);
MultiObjFnc=MultiObj.name;%问题名
% Parameters
params.Np=100; % Population size
params.Nr=200; % Repository size
params.maxgen=100; % Maximum number of generations
numOfObj=MultiObj.numOfObj;%目标函数个数
D=MultiObj.nVar;%维度
f=NSTROA(params,MultiObj);
X=f(:,1:D);%PS
Obtained_Pareto=f(:,D+1:D+numOfObj);%PF
if(isfield(MultiObj,'truePF'))%判断是否有参考的PF
True_Pareto=MultiObj.truePF;
%% Metric Value
% ResultData的值分别是IGD、GD、HV、Spacing (HV越大越好,其他指标越小越好)
ResultData=[IGD(Obtained_Pareto,True_Pareto),GD(Obtained_Pareto,True_Pareto),HV(Obtained_Pareto,True_Pareto),Spacing(Obtained_Pareto)];
else
%计算每个算法的Spacing,Spacing越小说明解集分布越均匀
ResultData=Spacing(Obtained_Pareto);%计算的Spacing
end
%%
disp('Repository fitness values are stored in Obtained_Pareto');
disp('Repository particles positions are store in X');
(2)部分结果

 简历投递
简历投递 商务合作
商务合作 媒体垂询
媒体垂询 微信二维码
微信二维码 微博二维码
微博二维码






